Welcome to Meta-Policy Search’s documentation!¶
Despite recent progress, deep reinforcement learning (RL) still relies heavily on hand-crafted features and reward functions as well as engineered problem specific inductive bias. Meta-RL aims to forego such reliance by acquiring inductive bias in a data-driven manner. A particular instance of meta learning that has proven successful in RL is gradient-based meta-learning.
The code repository provides implementations of various gradient-based Meta-RL methods including
- ProMP: Proximal Meta-Policy Search (Rothfuss et al., 2018)
- MAML: Model Agnostic Meta-Learning (Finn et al., 2017)
- E-MAML: Exploration MAML (Al-Shedivat et al., 2018, Stadie et al., 2018)
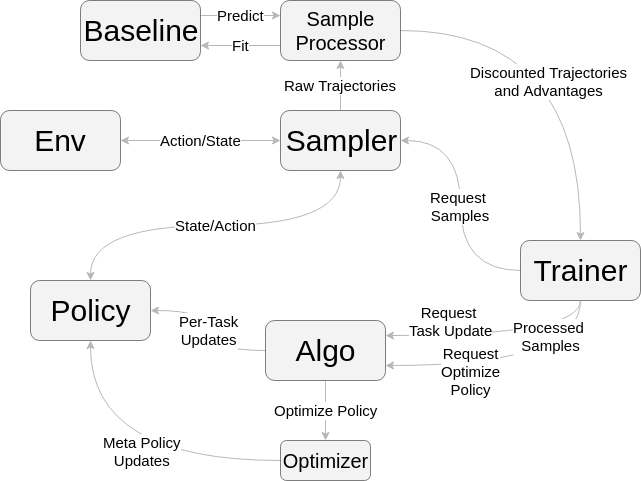
The code was written as part of ProMP. Further information and experimental results can be found on our website. This documentation specifies the API and interaction of the algorithm’s components. Overall, on iteration of gradient-based Meta-RL consists of the followings steps:
- Sample trajectories with pre update policy
- Perform gradient step for each task to obtain updated/adapted policy
- Sample trajectories with the updated/adapted policy
- Perform a meta-policy optimization step, changing the pre-updates policy parameters
This high level structure of the algorithm is implemented in the Meta-Trainer class. The overall structure and interaction of the code components is depicted in the following figure: